Physics-Based AI Image Detection
Can you detect AI-generated images by checking if they obey the laws of physics? That's the core question behind this project.
The Insight
AI image generators (DALL-E, Midjourney, Stable Diffusion) produce visually stunning images — but they don't actually understand physics. They approximate what scenes look like without modeling how light, depth, and surface interactions actually work.
This project exploits that gap.
Three Physics Pipelines
We extract 27 features from three complementary physics-based analysis pipelines, applied to 30 real images (COCO) and 30 AI-generated images (AIGenBench):
1. Depth Map Statistics
Using monocular depth estimation, we analyze the statistical properties of predicted depth maps:
- gradient mean/std — how sharply depth transitions occur
- skewness/kurtosis — asymmetry and tail behavior of depth distributions
- entropy — information content of the depth field
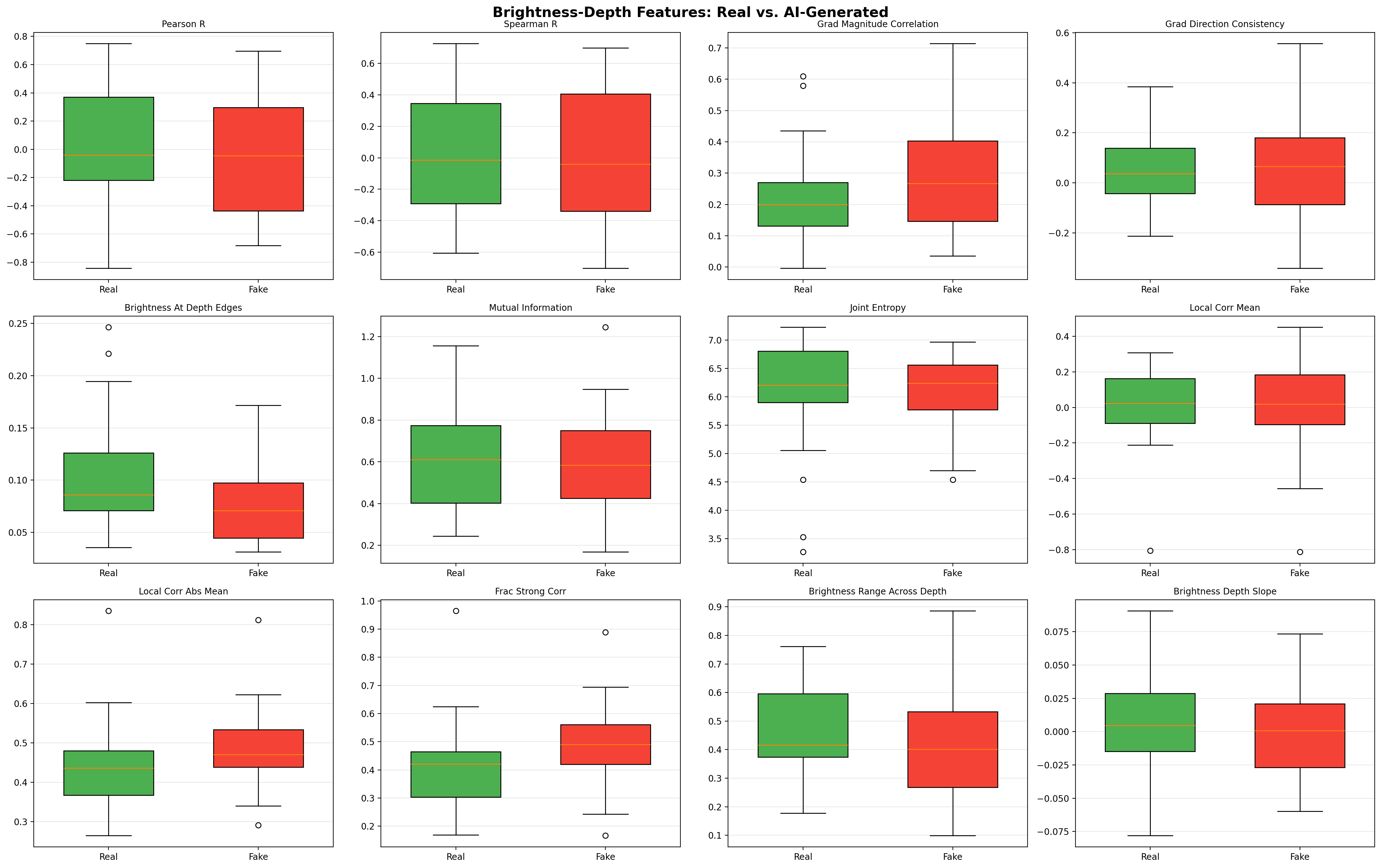
2. Brightness-Depth Consistency
In real photographs, brightness and depth are physically coupled — objects farther away tend to have different illumination characteristics. We measure:
- Pearson/Spearman correlation between brightness and depth
- Local patch correlations — spatial consistency of the brightness-depth relationship
- Brightness at depth edges — what happens to brightness where depth changes sharply
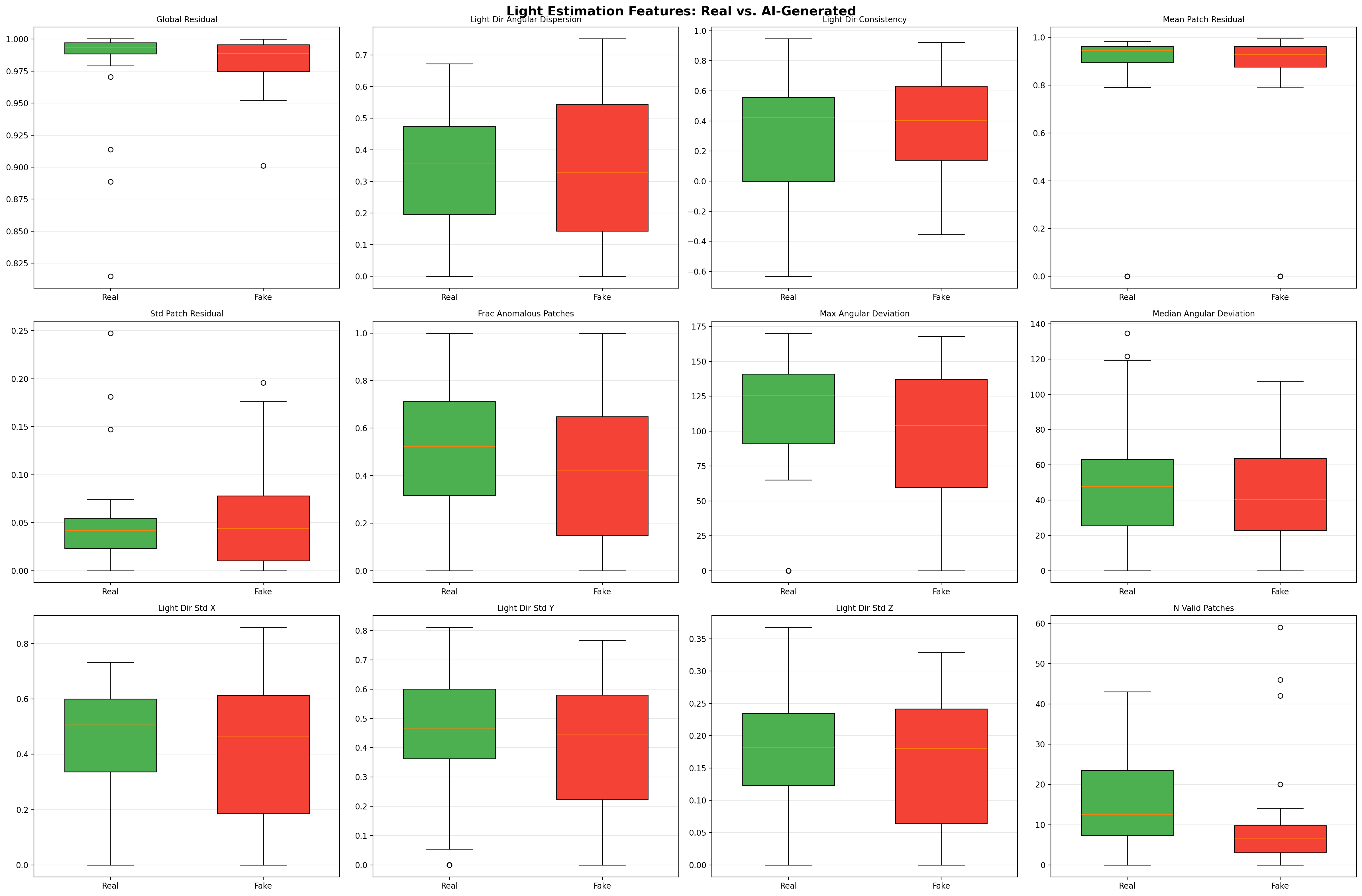
3. Light Estimation
Real scenes have consistent lighting from a single dominant source. AI-generated images often have subtle inconsistencies:
- Global residual — how well a single light model fits the scene
- Angular deviation — variance in estimated light direction across patches
- Fraction anomalous patches — percentage of regions with inconsistent lighting
Key Findings
The Paradox of AI Images
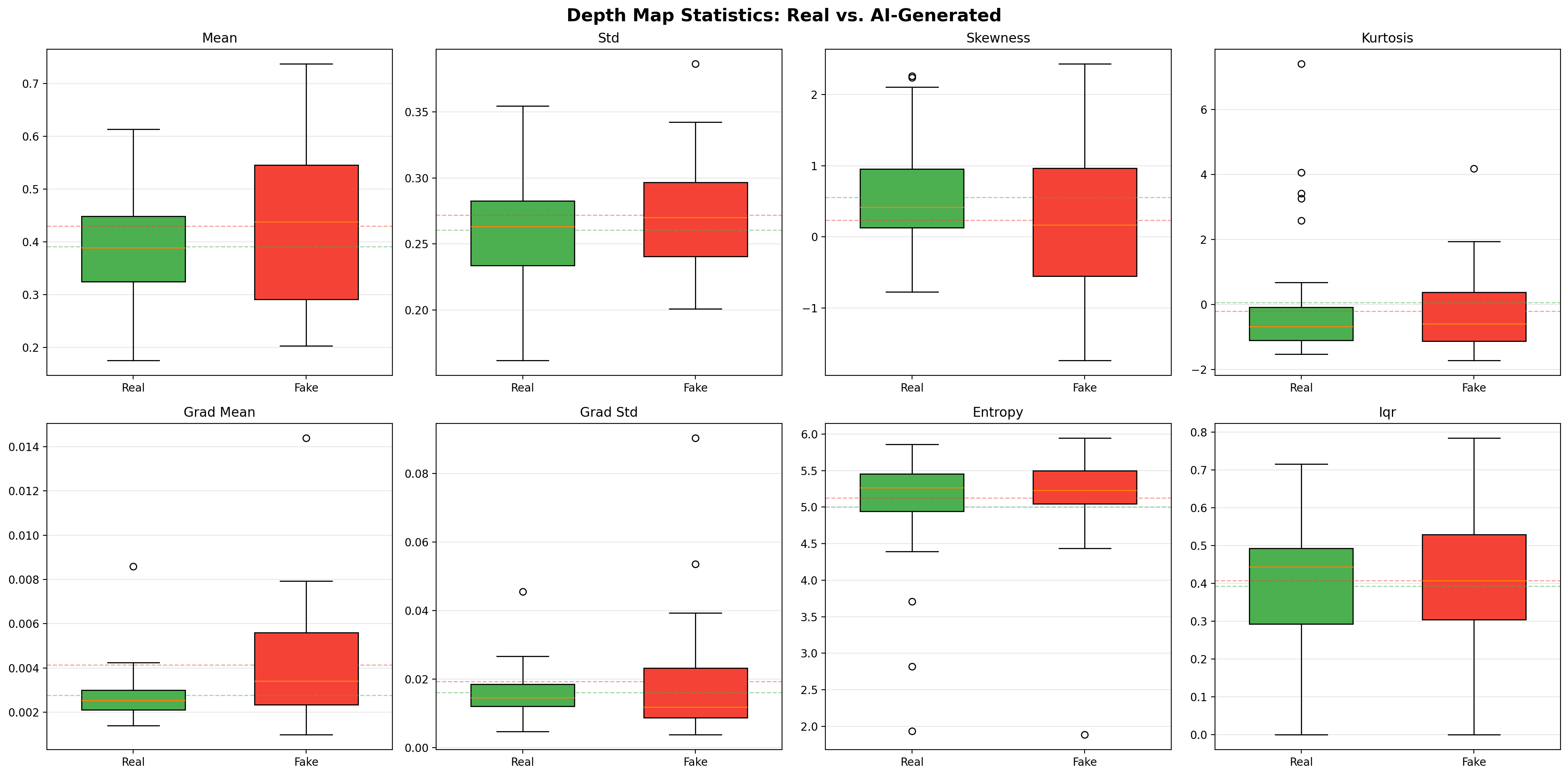
AI-generated images are simultaneously too consistent AND too sharp:
| Finding | What It Means |
|---|---|
| Smooth brightness-depth | AI produces overly uniform brightness-depth relationships (d=0.445) |
| Symmetric depth distributions | Real images have skewed depth (0.556 vs 0.236) — AI makes everything too balanced |
| More uniform lighting | Fewer anomalous patches in AI images (41% vs 51%) |
| But sharper depth gradients | AI images have abrupt depth transitions (d=0.653) — the strongest signal |
The last finding is the most interesting: AI generators create sharp, almost cartoon-like depth boundaries because they haven't learned that real-world depth transitions are gradual (due to actual 3D geometry, not learned textures).
Feature Ranking by Effect Size
The top discriminative features ranked by Cohen's d:
| Rank | Feature | Cohen's d | Direction |
|---|---|---|---|
| 1 | Depth gradient mean | 0.653 | Fake > Real |
| 2 | Brightness at depth edges | 0.547 | Real > Fake |
| 3 | Local correlation (abs mean) | 0.445 | Fake > Real |
| 4 | Fraction strong correlation | 0.428 | Fake > Real |
| 5 | Gradient magnitude correlation | 0.376 | Fake > Real |
| 6 | Depth skewness | 0.356 | Real > Fake |
| 7 | Fraction anomalous patches | 0.307 | Real > Fake |
Less Is More: The Classifier
We trained logistic regression classifiers with leave-one-out cross-validation:
| Model | Accuracy | F1 | Train Acc | Gap |
|---|---|---|---|---|
| All 27 features | 55.0% | 0.542 | 81.7% | 26.7pp |
| 3 features | 68.3% | 0.678 | 71.7% | 3.4pp |
The 3-feature model uses only grad_mean, brightness_at_depth_edges, and n_valid_patches — and generalizes far better because:
- 27 features overfit on 60 samples
- The top features capture complementary physics violations
- Minimal train/test gap (3.4pp) indicates genuine signal, not memorization
The Decision Rule
Classify as FAKE if:
1.43 × z(grad_mean) − 1.26 × z(brightness_at_depth_edges) + 0.04 > 0
Translation: an image is likely AI-generated if it has sharp depth gradients (doesn't understand 3D geometry) combined with low brightness variation at depth edges (doesn't understand light-surface interaction).
PCA Analysis
27 features compress into 6 principal components capturing ~77% of variance:
| PC | Variance | Interpretation |
|---|---|---|
| PC1 | 24.1% | Scene complexity (entropy, skewness, kurtosis) |
| PC2 | 15.3% | Lighting quality (angular deviation, anomalous patches) |
| PC3 | 13.8% | Brightness-depth coupling (pearson_r, spearman_r) |
| PC4 | 10.6% | Depth distribution shape (std, iqr, grad_mean) |
| PC5 | 7.5% | Information content (mutual_information) |
Critical insight: The real/fake signal is NOT the dominant axis of variation. Scene-level variation (complexity, depth range) dominates, which is why targeted feature selection outperforms using all features.
Limitations & Future Work
- Sample size: 30 images per class is a proof-of-concept — scaling to thousands would strengthen results
- Generator diversity: Tested on AIGenBench; extending to DALL-E 3, Midjourney v6, Flux would test generalizability
- Depth estimator dependency: Results depend on the quality of the monocular depth model
- Complementary approaches: Physics features could be combined with frequency-domain or learned detectors for higher accuracy
Conclusion
This project demonstrates that physics-based reasoning can detect AI-generated images without any training on specific generators. The key insight — AI images are paradoxically too consistent while having unnaturally sharp depth transitions — reveals a fundamental limitation of current image generators: they learn to approximate visual appearance without genuinely understanding the physical world that produces those appearances.