
Reasoning LLMs Are Rewriting What AI Can Think
The evolution from "fast-and-sloppy" to "slow-and-rigorous" reasoning in AI isn't just an incremental improvement — it's a paradigm shift. A new comprehensive survey from Li et al. (2025) maps the entire landscape of reasoning LLMs, from their cognitive science roots to the cutting-edge methods powering models like OpenAI's o1/o3 and DeepSeek's R1.
The Core Insight: Dual-Process Theory Meets AI
Cognitive science has long distinguished between two modes of human thought:
- System 1: Fast, automatic, intuitive — pattern matching without deliberation
- System 2: Slow, deliberate, analytical — step-by-step logical reasoning
Foundational LLMs (BERT, GPT-4, LLaMA) are essentially System 1 thinkers. They're brilliant at pattern completion but prone to hallucination, logical shortcuts, and brittle multi-step reasoning. The reasoning LLM revolution is about engineering System 2 into these models.
Survey Architecture
The survey organizes the field into a clean taxonomy:
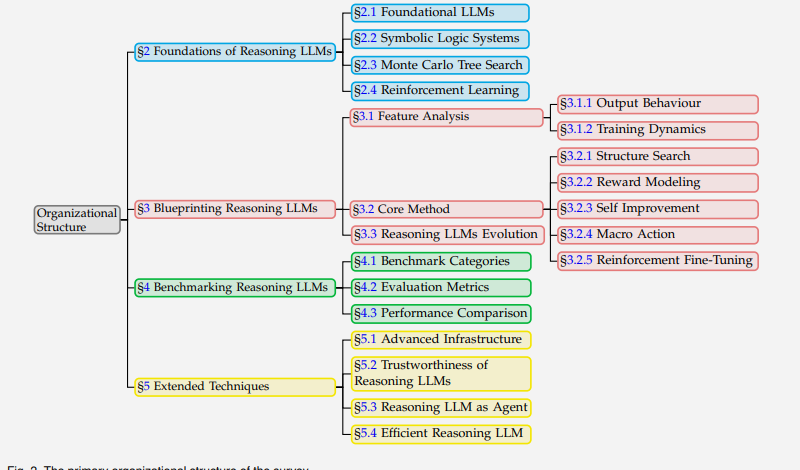 Fig. 2 from the paper: Primary organizational structure covering foundations, blueprinting, benchmarking, and extended techniques.
Fig. 2 from the paper: Primary organizational structure covering foundations, blueprinting, benchmarking, and extended techniques.
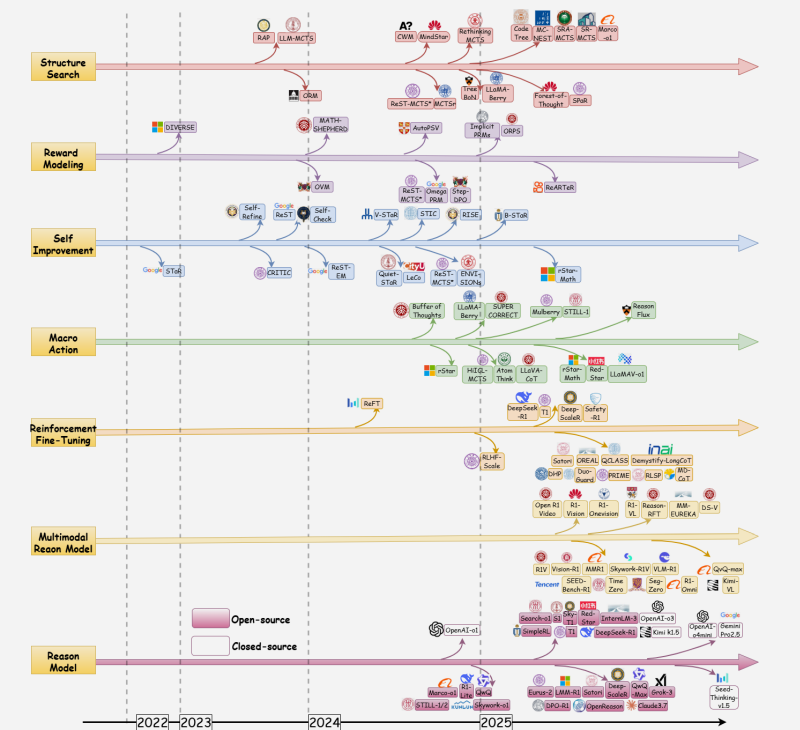
The Timeline: How We Got Here
Fig. 1 from the paper: Timeline of reasoning LLMs showing the evolution across structure search, reward modeling, self-improvement, macro action, reinforcement fine-tuning, multimodal, and complete reasoning models from 2022–2025.
The timeline reveals several important trends:
- Structure search (MCTS-based methods) exploded in mid-2024
- Reinforcement fine-tuning emerged as the dominant training paradigm by late 2024
- Multimodal reasoning models are the newest frontier (early 2025)
- The open-source vs closed-source divide is narrowing rapidly
Five Core Methods Driving the Transition
1. Structure Search (MCTS + Tree-of-Thought)
Instead of generating a single reasoning chain, these methods explore a tree of possible reasoning paths. Monte Carlo Tree Search (MCTS) uses the UCB1 formula to balance exploration and exploitation:
UCB1 = w_i/n_i + c × √(ln N / n_i)
Where w_i is the total reward, n_i is the visit count, N is the parent's visit count, and c balances exploration. This allows models to backtrack, try alternative reasoning paths, and converge on more reliable solutions.
Key models: AlphaLLM, LLaMA-Berry, Marco-o1, rStar-Math
2. Reward Modeling
Process Reward Models (PRMs) evaluate each intermediate reasoning step rather than just the final answer. This provides denser supervision signals:
- Outcome Reward Models (ORMs): Score the final answer only
- Process Reward Models (PRMs): Score each step in the reasoning chain
- Implicit PRMs: Derive step-level scores from language model probabilities
PRMs are particularly effective for math and code because correctness can propagate — one wrong step invalidates everything downstream.
3. Self-Improvement
Models learn to improve their own reasoning without human supervision:
- STaR (Self-Taught Reasoner): Generate rationales → filter correct ones → fine-tune → repeat
- SPIN: Self-play where the model tries to distinguish its own outputs from human ones
- Self-Rewarding LLMs: Models generate their own reward signals for iterative improvement
4. Macro Action Frameworks
These combine symbolic templates with neural generation:
- Hierarchical planning: High-level plan first, then detailed execution
- Symbolic integration: Embedding formal logic rules into the generation process
- Multi-agent decomposition: Breaking complex problems across specialized sub-agents
5. Reinforcement Fine-Tuning
The most impactful recent approach. Uses RL (PPO, DPO, GRPO) to optimize the reasoning process:
- DeepSeek-R1: Trained primarily with GRPO, achieving o1-level performance
- OpenAI o1/o3: Uses extensive RL to develop "thinking" behavior
- Journey Learning: Training on the full problem-solving process, not just final solutions
Benchmark Performance
Here's how the leading reasoning LLMs compare across key benchmarks:
| Model | AIME 2024 | MATH-500 | GPQA Diamond | LiveCodeBench | Codeforces |
|---|---|---|---|---|---|
| o3-mini (high) | 79.2% | 97.4% | 79.7% | — | 2130 |
| o1 | 74.4% | 96.4% | 87.7% | — | 1891 |
| DeepSeek-R1 | 79.8% | 97.3% | 71.5% | 65.9% | 2029 |
| QwQ-32B-Preview | 50.0% | 90.6% | 54.5% | — | — |
| Claude 3.5 Sonnet | 16.0% | 78.3% | 65.0% | — | — |
| GPT-4o | 9.3% | 76.6% | 53.6% | — | — |
The gap between reasoning LLMs (o1, o3, R1) and foundational LLMs (GPT-4o, Claude) is massive — often 3-8× on hard math benchmarks.
What's Different About Reasoning LLM Behavior
The survey identifies several distinctive output behaviors:
- Hypothesis generation → verification loops: Instead of one-shot answers, models generate candidates, evaluate them, and refine
- Self-correction: Models identify and fix their own errors mid-chain
- Extended inference: Thinking chains can run to thousands of tokens for complex problems
- Backtracking: Models explicitly abandon wrong paths and restart from earlier points
Interestingly, there's an "overthinking" problem — reasoning chains that are too long can actually hurt performance. The optimal chain length depends on problem difficulty.
The Agent Connection
This is where reasoning LLMs become transformative. Reasoning capabilities are the missing piece for autonomous AI agents:
- Planning: MCTS-style reasoning enables long-horizon task planning
- Tool use: Deliberate reasoning about which tools to invoke and when
- Self-verification: Agents can check their own work before acting
- Error recovery: Backtracking and replanning when actions fail
The survey covers ReAct, Toolformer, and emerging agentic reasoning frameworks that combine reasoning LLMs with external tools and environments.
Connection to My Research
The transition from System 1 to System 2 reasoning has direct implications for several areas I work on:
- Iterative distillation: The self-improvement loop (STaR, SPIN) closely mirrors the iterative distillation pipeline — both involve models bootstrapping better versions of themselves from filtered outputs
- Multi-agent architectures: Macro action frameworks and the decomposition strategies here inform how we design specialized agent systems
- Safety and alignment: Process reward models provide the kind of step-level supervision that's essential for keeping reasoning chains aligned with human values — especially relevant for safety-critical domains
Key Takeaways
- Reasoning is trainable: It's not an emergent capability from scale alone — specific training methods (RL, PRM, MCTS) reliably produce it
- Open-source is catching up: DeepSeek-R1 matches o1 on most benchmarks while being fully open
- Efficiency matters: Not every problem needs 10,000 tokens of reasoning — adaptive computation allocation is the next frontier
- Multimodal reasoning is nascent: Extending System 2 thinking to vision, audio, and video is largely unsolved
- Safety requires new approaches: Reasoning chains introduce new attack surfaces (prompt injection into intermediate steps, reasoning hijacking)
Paper Details
Title: From System 1 to System 2: A Survey of Reasoning Large Language Models
Authors: Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, et al.
Published: February 2025 (arXiv:2502.17419v6)
GitHub: Awesome-Slow-Reason-System